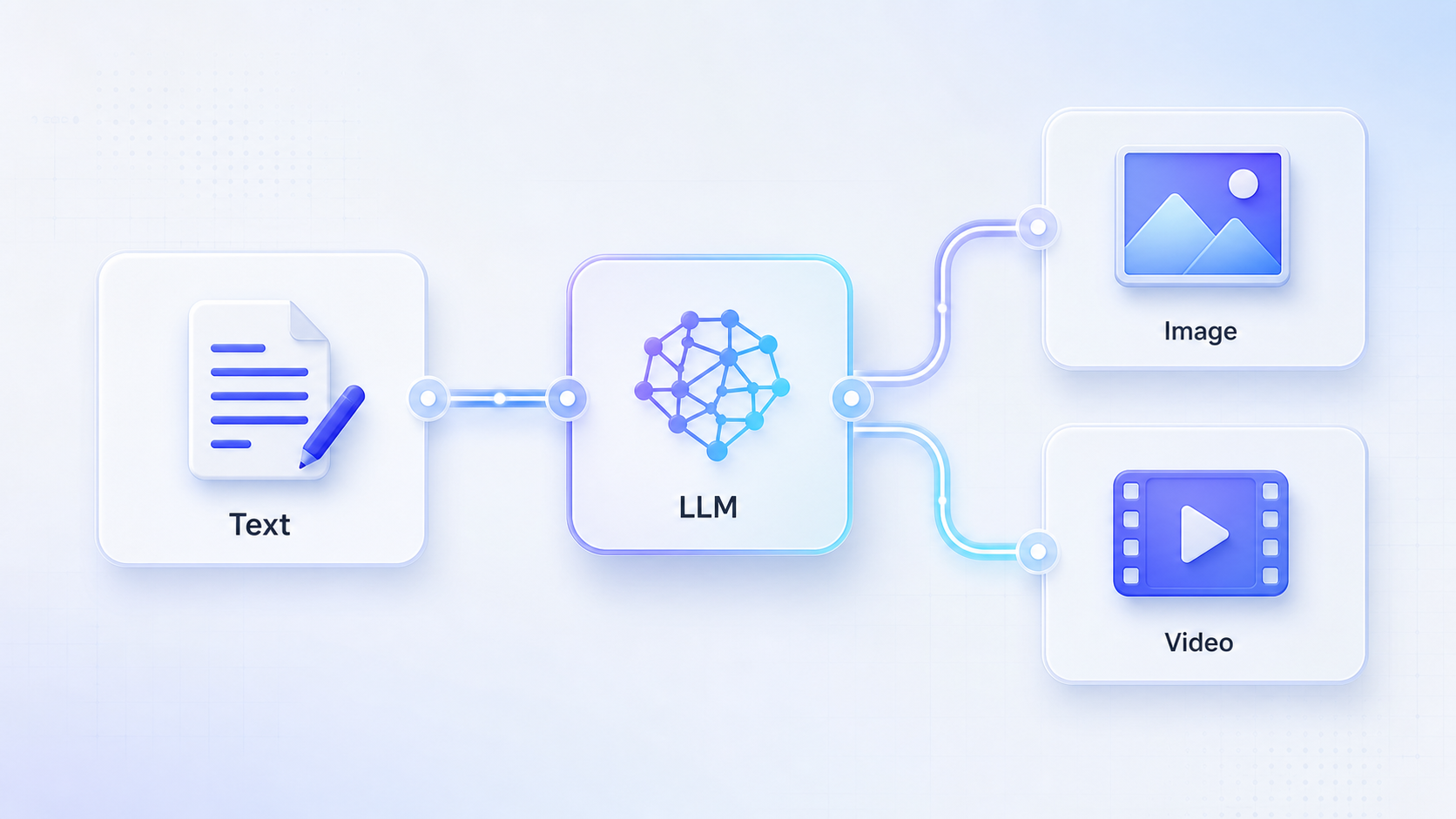
为什么中间要加 LLM
图片模型和视频模型更适合读取清晰、结构化、视觉化的提示词。用户随手写的一句话,通常信息不够。
在 RelayMe 工作流里,LLM 节点可以承担“提示词编剧”的角色:把普通需求改写成下游媒体模型更容易理解的提示词。
基础连接方式
第一步先创建文字节点。这个节点用于让用户写原始想法、产品描述、脚本或营销方向。
第二步把文字节点连接到 LLM 节点。在 LLM 的指令里,要求它把输入改写成视觉提示词,包含主体、场景、镜头、光线、风格、约束和输出格式。
第三步把 LLM 的输出连接到图片节点或视频节点的提示词输入。也就是说,媒体模型读取的是 LLM 生成后的提示词,而不是用户最初那段粗略文字。
一个想法同时生成图片和视频
当 LLM 输出稳定后,可以把它分支到多个生成节点。
例如,同一段结构化视觉提示词可以送到图片节点生成海报概念,也可以送到视频节点生成动态短片。如果视频需要更细的镜头语言,可以在视频节点前再加一个 LLM 节点,把提示词改写成分镜描述。
可直接使用的 LLM 指令
你可以这样写 LLM 指令:请把用户输入改写成清晰的图片或视频生成提示词。包含主体、环境、视觉风格、镜头角度、光线、氛围、构图和负面约束。只返回最终提示词。
这样工作流会更可控,也更容易复用到不同产品、脚本或创意简报中。