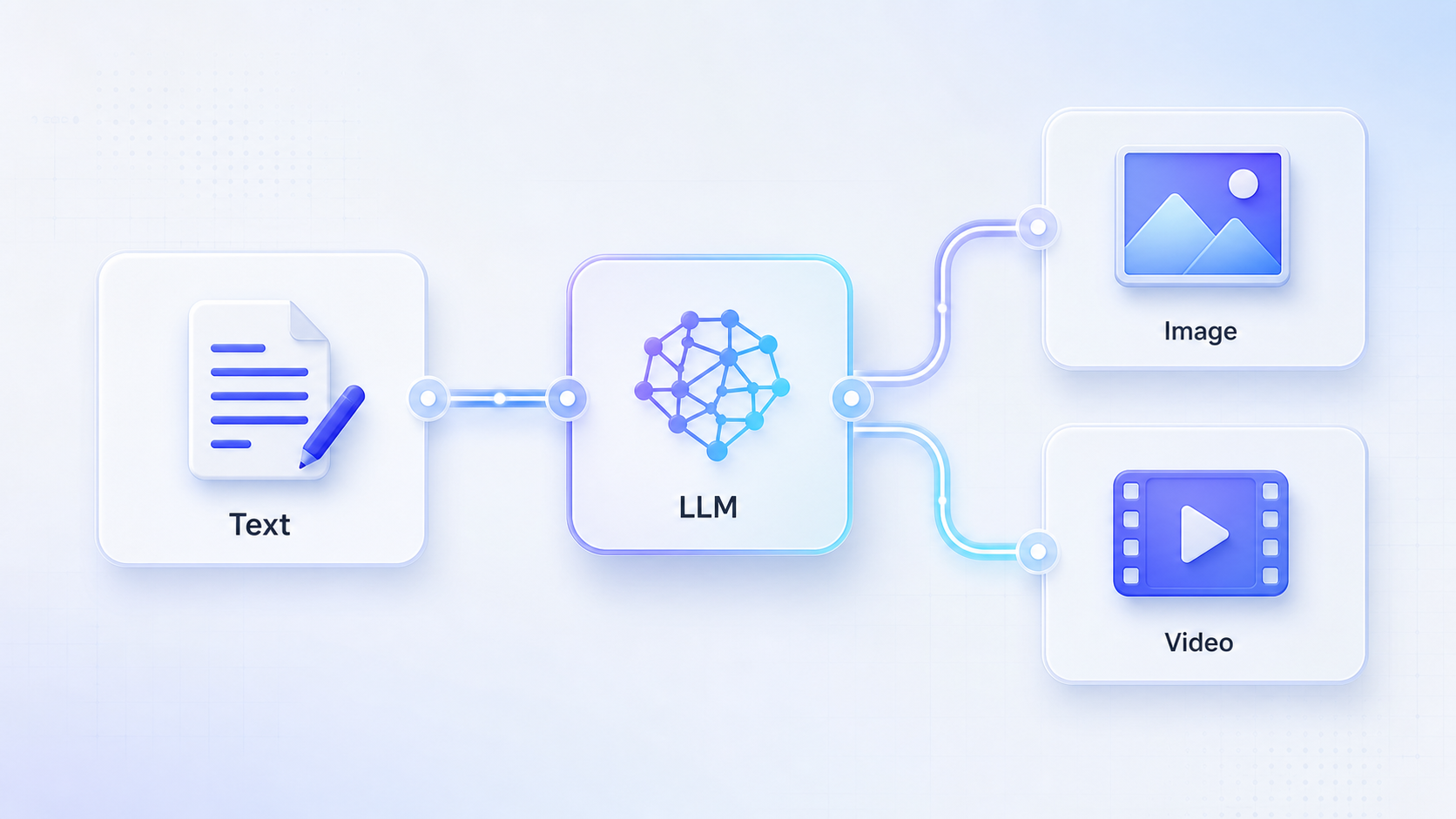
為什麼中間要加 LLM
圖片模型和影片模型更適合讀取清晰、結構化、視覺化的提示詞。用戶隨手寫的一句話,通常資訊不夠。
在 RelayMe 工作流裡,LLM 節點可以承擔「提示詞編劇」的角色:把普通需求改寫成下游媒體模型更容易理解的提示詞。
基礎連接方式
第一步先建立文字節點。這個節點用於讓用戶寫原始想法、產品描述、腳本或行銷方向。
第二步把文字節點連接到 LLM 節點。在 LLM 的指令裡,要求它把輸入改寫成視覺提示詞,包含主體、場景、鏡頭、光線、風格、約束和輸出格式。
第三步把 LLM 的輸出連接到圖片節點或影片節點的提示詞輸入。也就是說,媒體模型讀取的是 LLM 生成後的提示詞,而不是用戶最初那段粗略文字。
一個想法同時生成圖片和影片
當 LLM 輸出穩定後,可以把它分支到多個生成節點。
例如,同一段結構化視覺提示詞可以送到圖片節點生成海報概念,也可以送到影片節點生成動態短片。如果影片需要更細的鏡頭語言,可以在影片節點前再加一個 LLM 節點,把提示詞改寫成分鏡描述。
可直接使用的 LLM 指令
你可以這樣寫 LLM 指令:請把用戶輸入改寫成清晰的圖片或影片生成提示詞。包含主體、環境、視覺風格、鏡頭角度、光線、氛圍、構圖和負面約束。只返回最終提示詞。
這樣工作流會更可控,也更容易複用到不同產品、腳本或創意簡報中。